Большие данные и биоинформатика
Число пользователей фейсбука в два раза меньше числа пар нуклеотидов в человеческом геноме. Огромные массивы информации накапливаются в самых разных областях, от соцсетей до биологии. Технология работы с большими данными дает возможность превратить терабайты информации в научное знание.
В сентябре 2008 года редактор журнала Nature Клиффорд Линч выпустил спецномер про то, как технологии работы с большими объемами данных могут повлиять на будущее науки. После этого на свет появился термин Большие Данные (Big Data), который сейчас уже используется далеко за пределами академической научной среды. Например, стратегия эффективного продвижения товаров, которая основывается на сборе всей доступной информации о покупателе, чтобы спрогнозировать, что же он захочет купить в будущем. Ну и, разумеется, вовремя предложить ему купить нужный товар в нужное время и в нужном месте.
Как пример можно вспомнить скандальную историю, когда одна торговая сеть стала присылать 12 летней девочке предложения с товарами для молодых мам. Рассерженные родители направились в магазин, чтобы выяснить причину этого недоразумения, и торговая сеть уже была готова принести извинения, однако спустя некоторое время выяснилось, что девочка действительно была беременна. Алгоритмы, основанные на анализе изменений в поведении беременных покупательниц, смогли увидеть то, чего не увидели даже родители ребенка. Однако, оставим этическую составляющую подобных методов и их использование в сугубо коммерческих целях, и вернемся к истокам – к большим данным в науке.
Что такое большие данные? Под этим термином подразумеваются методы обработки и получения недоступной ранее информации из огромного массива разнородных данных. Объем подобных данных может занимать тысячи и сотни тысяч терабайт, при этом данные могут быть не структурированными, неполными, повторяющимися и с ошибками. Такие данные надо где-то хранить, а также быстро и эффективно обрабатывать. Все это техническая сторона вопроса, без развития которой не возникло бы самого феномена больших данных. Но, помимо «железа», должны быть еще и алгоритмы, которые из этого океана цифр смогут получить новую информацию. Здесь можно провести сравнение со знаменитым рычагом Архимеда, которому нужно была лишь точка опоры, чтобы продемонстрировать силу своего закона и поднять Землю. Технологии больших данных сейчас играют роль рычага и точки опоры, с помощью которых стали возможны недоступные раньше вещи. Однако кому, кроме торговых сетей, может понадобится «поднимать Землю»?
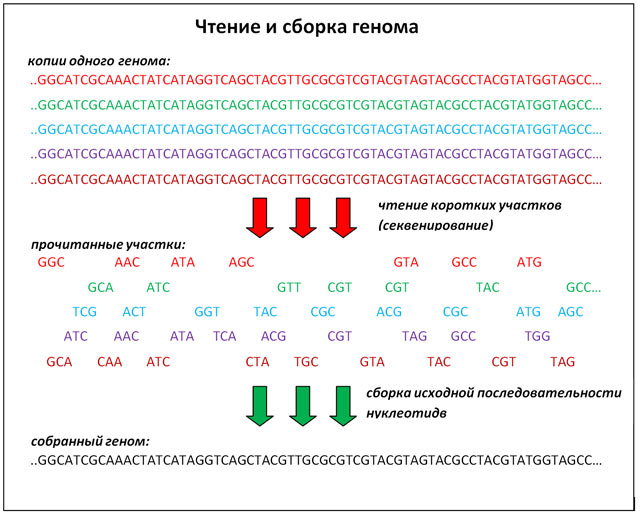
Одним из активных пользователей больших данных стала биоинформатика, которая за последние десятилетие сделала огромный скачек в своем развитии. В 2003 году был впервые расшифрован геном человека. Тогда это потребовало привлечения огромного количества ресурсов стран со всего мира, а стоимость проекта исчислялась сотнями миллионов долларов. Однако уже через десять лет стоимость секвенирования генома упала до нескольких тысяч долларов, что сделало ее на порядки более доступной.
Сейчас в лабораториях и медицинских центрах идет накопление генетических данных отдельных пациентов, существуют международные проекты, целью которых ставится создание баз данных геномов тысяч и даже миллионов людей. Именно этот объем данных может стать источником абсолютно новой информации о функциях и работе нашего генетического кода. Генетические данные требует огромных емкостей для хранения. Например, результаты секвенирования генома одного человека могут занимать до сотни гигабайт. Если к ним добавить другие оцифрованные данные о пациенте, будь то результаты анализов или данные томографии, то объем уже приближается к терабайту. Поэтому хранение и обработка такого массива информации требует методов как раз таки из серии «больших данных».
Такие задачи привели к объединению усилий разработчиков IT-решений и исследователей, занимающимися проблемами биоинформатики и вычислительной биологии, для создания простых и эффективных инструментов для работы с генетическими данными.
Примером такого взаимодействия можно назвать сотрудничество лаборатории алгоритмической биологии Санкт-Петербургского академического университета РАН и Центра разработок и исследований компании ЕМС, целью которого стало упрощение диагностики онкологических заболеваний при помощи РНК-секвенирования. В лаборатории разрабатываются новые подходы к секвенированию и сборке геномов. Один из перспективных проектов – РНК-ассемблер SPAdes, программа, которая из сотни тысяч отдельных кусков генома, полученных в результате секвенирования, собирает его целиком.
Такую задачу можно сравнить со сборкой паззла, в котором сотни тысяч элементов одинаковых цветов, часть элементов потеряна, а часть вообще из другой коробки. Инженеры центра ЕМС, со своей стороны, разработали платформу, которая позволяет обрабатывать, хранить и анализировать огромный объем генетической информации. Объединение науки и инженерных технологий позволит результатам исследователей сойти со страниц научных журналов и принести конкретную пользу людям сегодня.
«IT-бизнес играет все возрастающую роль не только в создании новых продуктов и технологий, но и в сфере науки и образования, – отмечает Камиль Исаев, генеральный директор "Центра исследований и разработок EMC". – Будучи драйвером развития общества, лидирующие IT-компании, такие, как EMC, вносят значительный вклад в то, каким наш мир будет завтра. Например, развитие информатики невозможно без работы с огромными массивами данных, которые необходимо хранить, обрабатывать и анализировать. Больше того, почти каждая наука сейчас вбирает в себя элементы computer science и работу с большими данными.
Закономерно, что научное сообщество выбирает в партнеры компании с экспертизой в этой сфере. Я бы сказал даже, что сближение науки и IT-бизнеса идет с двух сторон. Да, ученые регулярно обращаются к IT-компаниям, но и IT-компании привлекают лучших специалистов в университетах и исследовательских лабораториях для решения своих задач. Мы в EMC активно сотрудничаем с Российской Академией наук в проекте по РНК-секвенированию, а например, Google сотрудничает с UC Berkeley и другими университетами в проектах, связанных с созданием беспилотных автомобилей».
По материалам СПбАУ РАН и НИЦ ЕМС
31 июля 2015
Статьи по теме: